The Latency Challenge: When Retrieval Slows Down Generation
Product managers and implementation teams face a common paradox with standard RAG systems: the more accurate the system, the slower and more expensive it becomes.
Traditional RAG systems, whether vector-only or hybrid, treat every user query the same way:
- Mandatory Retrieval: Every query, simple or complex, triggers a search across the entire vector index.
- Fixed Latency: This compulsory retrieval adds a measurable latency penalty to every response.
- Increased Cost: Retrieval consumes resources and unnecessarily loads the context window of the LLM, increasing token usage and API costs, especially for simple questions.
For high-volume applications, executing an expensive retrieval step for an easily answerable question (like "What is our phone number?") is wasteful. The latest trend addressing this issue is Adaptive RAG, which introduces a dynamic routing layer to optimize the process.
What is Adaptive RAG? Dynamic Routing for Query Intelligence
Adaptive RAG is an advanced architecture that uses a meta-LLM or a classification model to analyze the user's intent and complexity before engaging the full retrieval system. It skips unnecessary steps, adapting the workflow to the specific needs of the query in real time.
It introduces a crucial triage point, shifting the process from a linear flow to a dynamic, branching path.
The Three Core Mechanisms of Adaptive RAG
Adaptive RAG systems generally employ one or more of these dynamic routing mechanisms:
-
Query Complexity Classification:
The system immediately classifies the query as Simple (internal LLM knowledge is sufficient, e.g., definitions, common facts) or Complex (requires external data, calculation, or multi-hop reasoning).
Mechanism: Simple queries bypass the vector store entirely, reducing latency by milliseconds and saving on retrieval compute costs.
-
Self-Correction/Rephrasing:
If the initial LLM output is flagged as low confidence or incomplete (often by an internal confidence score model), the query is automatically rephrased and routed back to the retrieval step.
Mechanism: Ensures that simple questions are answered fast, but difficult questions don't fail silently.
-
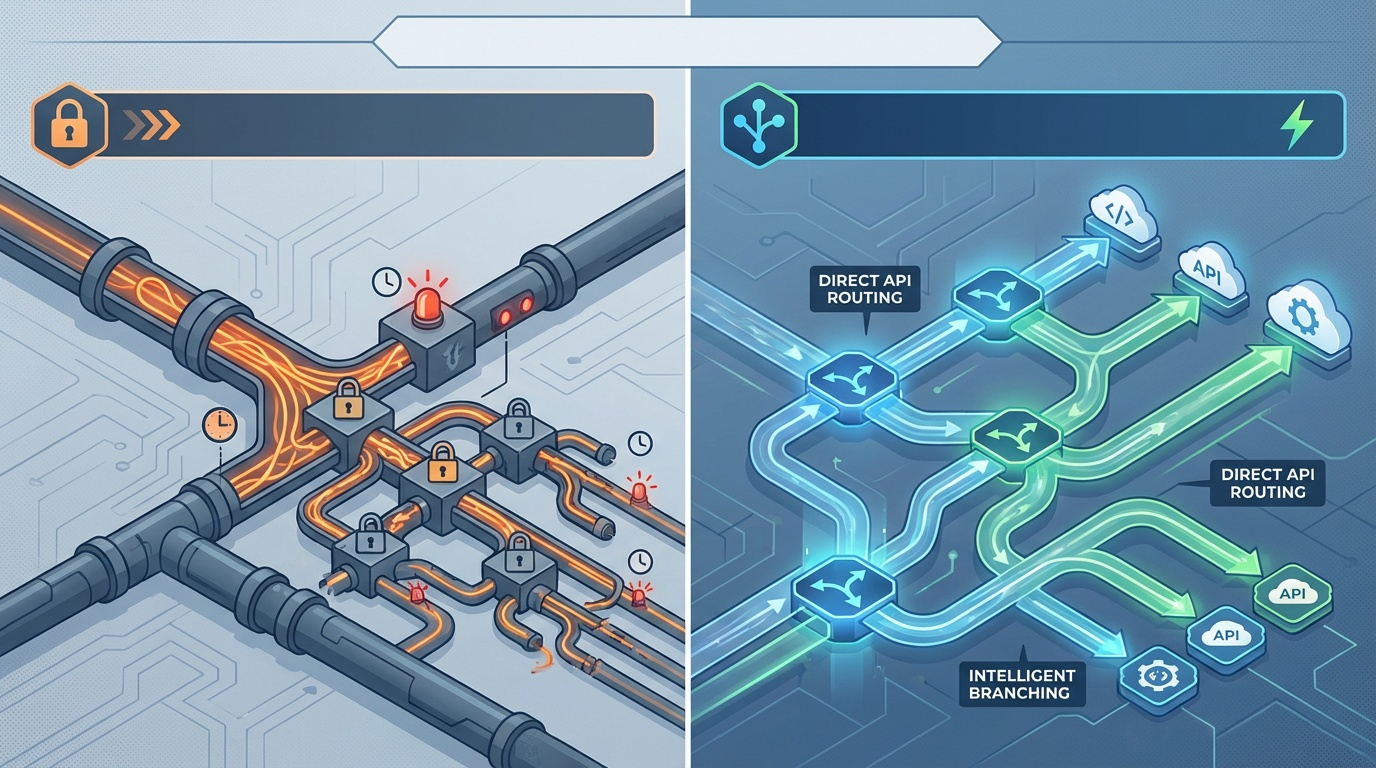
Tool/Data Source Routing:
For very specific queries (e.g., "What is the balance of Account X?"), the system uses the extracted entities to route the query directly to the relevant tool or API (e.g., a live database lookup) rather than the general vector store.
Mechanism: Improves precision by querying the canonical source of truth immediately, skipping the document indexing step entirely.
Business Value: Latency Reduction and Cost Control
For product and implementation teams, Adaptive RAG is a direct lever for improving key performance indicators (KPIs):
| Performance Metric | Adaptive RAG Impact | Business Outcome |
|---|---|---|
| P95 Latency | Skips retrieval step for 30–50% of queries (e.g., simple definitions, common FAQs). | Faster User Experience: Critical for real-time applications and reducing user drop-off. |
| API Costs (Tokens) | Context window is smaller because only necessary facts are retrieved, not extraneous document chunks. | Reduced Operating Costs: Lower monthly spend on LLM API calls, improving project ROI. |
| System Reliability | Dynamically routes queries to specialized tools (e.g., calculators, APIs). | Higher Factual Confidence: Answers requiring live data bypass the document vector index. |
How It Works: A Simplified Walkthrough
Here is the operational flow of an Adaptive RAG system for a query like "What is the company's Q4 revenue?"
- Query Intake: User asks the question.
- Triage Model: A lightweight model analyzes the query. It identifies "Q4 revenue" as requiring a specific, live data look-up and not general document context.
- Dynamic Routing: The system routes the query away from the vector store and directly to the Finance Reporting API Tool.
- Tool Execution: The API returns the raw revenue number from the live database.
- Generation: The LLM receives the prompt: "State the following number (125.7 million) in a professional summary."
The retrieval latency is eliminated, and the risk of hallucination referencing old documents is zeroed out because the information came directly from the primary system of record.